Components
The Component class is designed to store structured data for a specific real “object” of “concept” in the system being
modeled. Components can take the form of generators, transmssion paths, policies, etc. Data is stored in specified
“attributes” for the Component.
Kit CSV File Format
All kit components have a standard CSV file format. The behavior of how these CSV files are read in is described
below:
- classmethod Component.from_csv(filename)
Create Component instance from CSV input file.
The CSV input file must have the following mandatory three-column format, with two optional columns (column order does not matter; however, column header names do matter):
timestamp
attribute
value
unit (optional)
scenario (optional)
[None or timestamp (hour beginning)]
[attribute name]
[value]
[unit name]
[scenario name]
Units
Unit conversion is handled by the
pintPython package. Expected attribute units are hard-coded in the Python implementation. If the pint package can find an appropiate conversion between the user-specified input of the attribute and the expected unit, it will convert data automatically to the expected unit.For example, if the expected unit is MMBtu (named as million_Btu or MBtu in pint), a user can easily enter data in Btu, and the code will automatically divide the input value by 1e6.
Scenarios
Scenarios are handled via an optional scenario column. Scenario handling is done via some clever pandas DataFrame sorting. In detail:
The
scenariocolumn is converted to a `pd.Categorical`_, which is an ordered list.The
scenariocolumns is sorted based on the Categorical ordering, where values with no scenario tag (None/NaN) are lowest-priority.The method
df.groupby.last()is used to take the last (highest-priority) value (since the dataframe should be sorted from lowest to highest priority scenario tag).Scenario tags that are not listed in scenarios.csv will be ignored completely (dropped from the dataframe).
Duplicate Values
If an attribute is defined multiple times (and for a timeseries, multiple times for the same timestamp), the last value entered in the CSV (i.e., furthest down the CSV rows) will be used.
- Parameters:
filename – Name of CSV input file. Defaults to
attributes.csv.scenarios – List of optional scenario tags to filter input data in file. Defaults to [].
data – Additional data to add to the instance as named attributes. Defaults to {}.
Referencing Other CSVs for Timeseries Data
To keep the
attributes.csvshorter, user can optionally enter the value of a timeseries as a file path to another CSV file instead of entering each timestamped data value inattributes.csv. This is done by using theNonetimestamp and entering a string filepath for the value. Absolute paths are preferred for the sake of being explicit, though relative paths will be parsed relative to the top-levelnew-modeling-toolkitfolder.There are two limitations of this functionality:
It is not currently possible to “mix-and-match” timeseries data specified in the attributes.csv file and from other referenced CSV files. You must either (a) input timeseries data in
attributes.csvwith timestamps or (b) use theNonetimestamp and reference a different file.Timeseries data read from another CSV file does not currently benefit scenario-tagging capabilities. The filepath references themselves in
attributes.csvcan be scenario-tagged; however, the other CSV file is just read in as if it were apd.Serieswith a DateTimeIndex.
- Returns:
Instance of Component class.
- Return type:
Understanding the Scenario Tagging “Layer Cake”
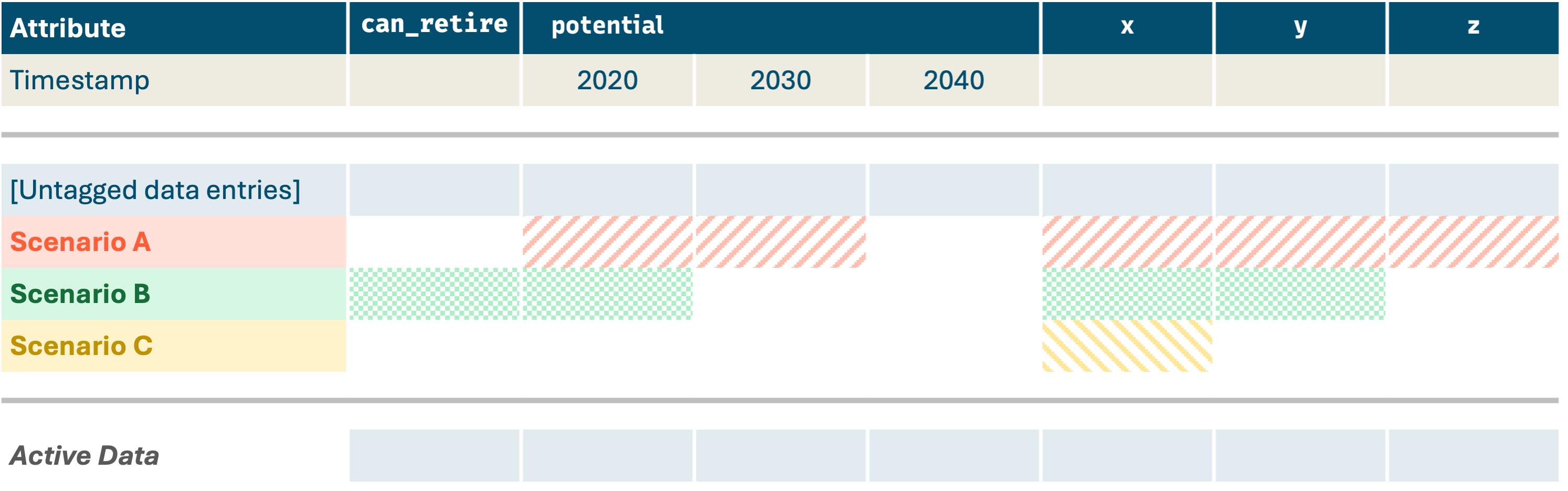
If no scenarios are active in the model run, then only the untagged data (and any default data for attributes that aren’t specified in the CSV file) get used. All other data in the CSV file gets ignored.
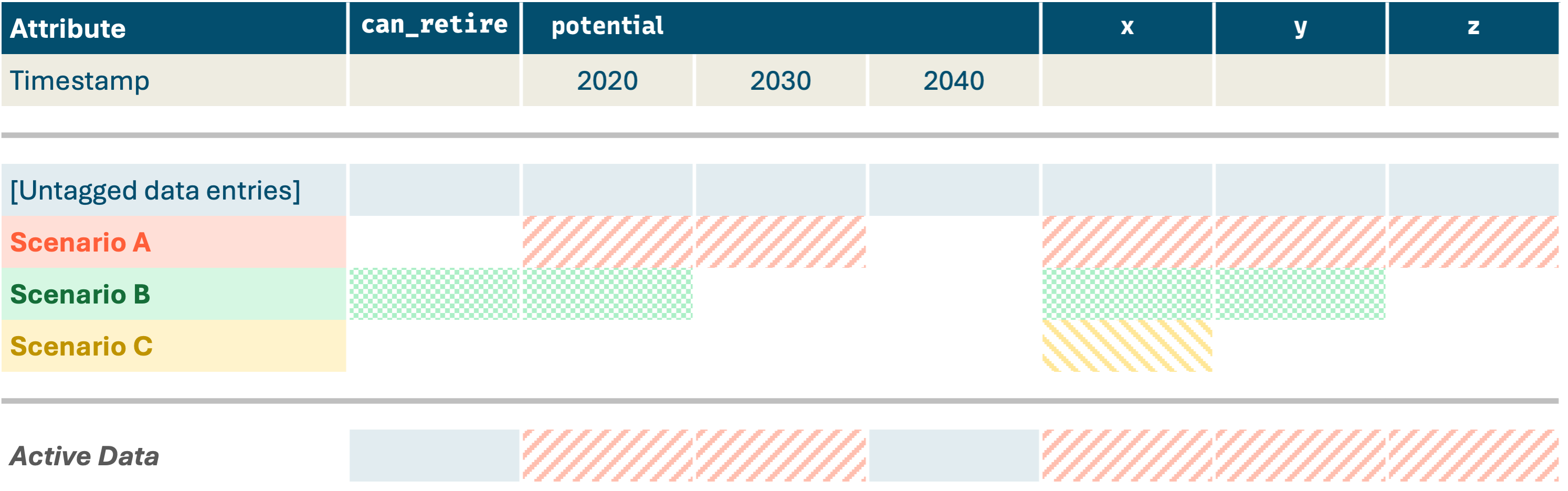
If Scenario A is active, then data tagged with that scenario (indicated as cells with red stripe shading) supersede
the untagged & default data. For example, the resource potential in 2020 & 2030 get overridden, as well as attributes
x and y.
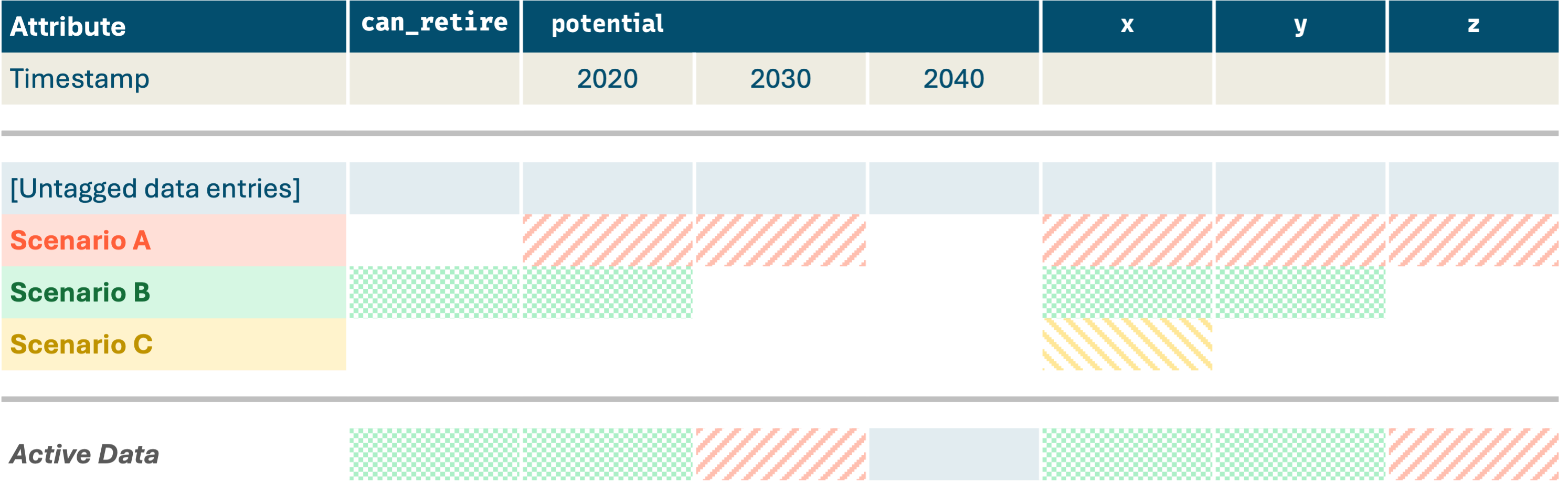
The layer cake continues with additional scenarios…
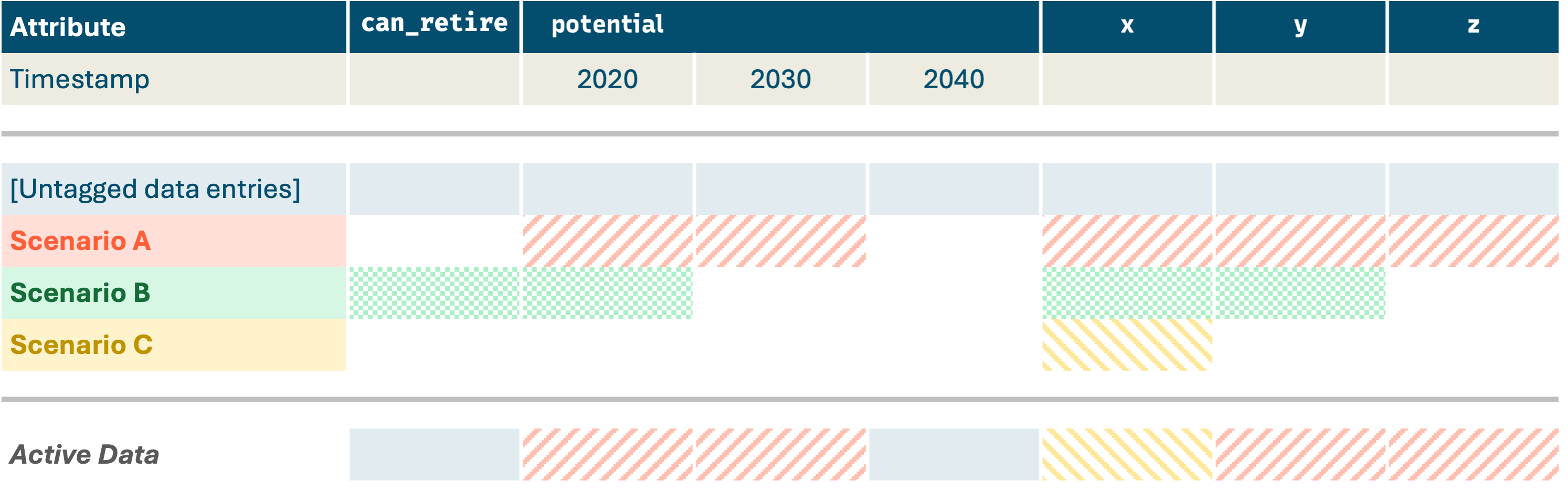
The layer cake continues with additional scenarios…
Warning
There is currently one exception to the “layer cake” analogy above. If timeseries data is input in the CSV file as a filepath to another CSV file, then no data from previous layers of the scenario tagging layer cake will be used (i.e., only the data from the other timeseries CSV file will be considered).